Isaiminia World Breaking News & Top Stories
Isaiminia World Breaking News & Top Stories
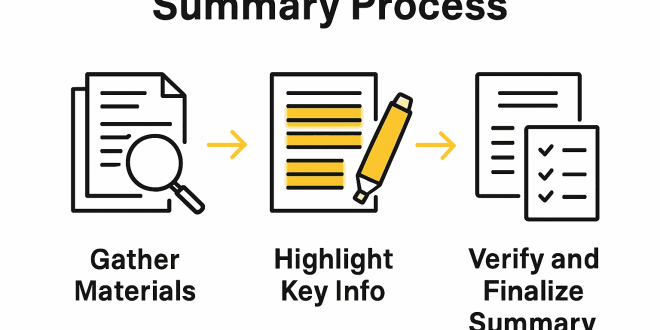
Managing the daily influx of digital text constitutes a massive operational hurdle for modern researchers, corporate analysts, and academic scholars. Web publications often bury key data points beneath long introductory stories, heavy promotional banners, and circular arguments. Manually filtering out this auxiliary fluff strains cognitive focus and drains valuable working hours. Algorithmic parsing systems offer an elegant solution to this saturation problem, automatically extracting core arguments and presenting clean, simplified overviews in seconds.
The Computational Architecture of Content Condensation
To condense a sprawling web page into an actionable digest, text processing systems rely on deep natural language processing models and extractive semantic maps. The underlying software evaluates structural document frameworks, identifying main thesis statements, supporting evidence, and quantitative analytical metrics. It calculates word relevance scores by looking at vocabulary clustering patterns across individual text blocks.
Once the central theme is isolated, the summarization engine strips away non-essential elements like advertising scripts, tracking pixels, and repeated rhetorical decorations. The framework then compiles the remaining data into organized bulleted sections or concise paragraphs. Users direct this process by adjusting length parameters or specific focus targets, ensuring that the exported brief answers their primary study goals without introducing narrative errors during intense extraction cycles.
Bypassing Operational Blockades in Digital Research
The efficiency of a content scanning routine depends heavily on the source material availability and target site accessibility. Researchers attempting to verify breaking news reports, view analytical whitepapers, or consult niche academic journals frequently run into technical barriers. Pop-up subscription demands, strict account registration gates, and hard payment boundaries disrupt automated analysis pipelines and break research focus.
These constant access interruptions force independent copywriters and media analysts to find direct, flexible extraction engines. To build seamless data collection loops, tech-savvy developers often deploy a Smry AI configuration within their standard browsing stack. Using a direct reading assistant lets you pull essential article substance straight from underlying webpage source code, allowing smooth information retrieval even when faced with restrictive overlay grids or annoying commercial script filters.
Professional Benefits and Studio Workflow Integration
Using predictive distillation systems introduces profound structural advantages across online competitive analysis, legal document verification, and educational content planning. In professional digital marketing divisions, reviewing dozens of competitor product launch outlines and industry whitepapers every morning becomes an effortless routine. Production teams can extract vital strategy trends and draft internal summaries without clicking through endless separate website layouts.
Concept writers for independent news websites and multimedia platforms also use these processing utilities to verify factual source materials rapidly. Compiling verified data packets from multiple overlapping reports allows editorial departments to build comprehensive overviews with greater speed and reliability. This rapid background check prevents writing rooms from repeating unverified rumors, saving considerable fact-checking resources before authorization of finalized publishing lists.
Optimizing Input Links for Coherent Extraction Output
The visual text alignment and accuracy of an automated data summary stay tied to the baseline formatting properties of your source page URL. Feeding addresses from websites that use non-standard database structures, highly fragmented comment feeds, or heavy dynamic script variations can occasionally lead to extraction anomalies. Clean article layouts with well-defined header marks provide the text patterns required for flawless semantic mapping.
Managing target text dimensions within your chosen web reading console also determines output clarity. Keeping summary lengths configured at balanced mid-points ensures that the algorithm retains critical context, conditional statements, and key statistics. This precision step is absolutely critical when handling highly specialized subjects, such as legal briefs or medical field updates, where removing a single phrase could warp the original meaning completely.
Processing Architectures and Operational Speed
Choosing between remote cloud infrastructure or relying on custom, locally installed client browser frameworks involves reviewing immediate system hardware capabilities and project privacy rules. Remote server platforms execute complex text scanning commands instantly, permitting users to manage long article distillation queues from basic smartphones or entry-level tablets. Conversely, using local browser integrations ensures complete privacy for proprietary project documentation, though it requires sufficient computing resources to manage live data streams smoothly.
As semantic language models continue to evolve, automated summarization utilities will synthesize long-form knowledge books with complete contextual accuracy. By mastering core prompt directions and choosing flexible, direct reading frameworks, content creators can successfully integrate automated article parsing into their regular professional routines today.